
Feature-Orbit Attractors
A Conceptual Framework for Bounded, Self-Correcting, Low-Power AI Inference
Concept paper. Proposed mechanisms only. Not presented as experimentally validated.
Abstract
Modern AI inference is computationally expensive, memory-intensive, and increasingly energy-constrained. At the same time, many neural systems operate probabilistically and may tolerate bounded approximation, stochasticity, and noise better than traditional exact digital computation. This paper proposes a conceptual framework for future AI inference systems that combine analog or mixed-signal computation, hardware-aware training, scientific control principles, and bounded representational geometry.
The central proposal is the use of learned feature-orbits or stable representational manifolds that allow normal variation while applying increasingly strong restorative forces as internal states drift away from learned valid regions. This is not presented as an experimentally validated architecture, but as a plausible engineering direction. The framework may be especially relevant to low-power AI accelerators, analog compute-in-memory systems, photonic inference hardware, robotics reflex systems, and long-running autonomous agents where bias, drift, noise, and compounding error must be bounded rather than merely ignored.
Key concepts introduced here include controlled inference, feature-orbit attractors, restorative orbit fields, manifold gravity inversion, hardware temperament profiles, and representational reflex circuitry.
Introduction
AI models are becoming more capable, but the energy and hardware requirements of large-scale inference remain a serious constraint. Datacenter electricity demand is projected to rise significantly, and AI inference is one of the pressures driving interest in smaller models, quantization, specialized accelerators, analog compute-in-memory, photonic computation, neuromorphic systems, and hybrid inference architectures.
Most current AI systems rely on general-purpose digital hardware or digital accelerators optimized for tensor operations. This approach is powerful and flexible, but it is also expensive in terms of memory movement, energy use, and latency. A possible long-term direction is to shift more inference work into hardware substrates that naturally perform useful mathematical operations. In such systems, the model is not merely executed by hardware. Portions of the model may be encoded into the physical behavior of the hardware itself.
This raises an important problem: physical systems are noisy. Analog memory cells drift. Photonic systems accumulate noise and precision limits. Neuromorphic systems operate through sparse, event-driven approximations. If future inference systems are to use such substrates, then AI models must not merely tolerate noise accidentally. They should be designed, trained, and monitored with noise as an expected operating condition.
This paper proposes a conceptual response: treat inference as a controlled experiment inside a bounded representational space. The system should use calibration probes, sentinel statistics, learned manifolds, and restorative forces to prevent drift, bias, and compounding error from accumulating without detection.
Background and Motivation
A large portion of neural inference cost comes from moving model weights and intermediate activations between memory and compute units. Analog compute-in-memory attempts to reduce this cost by colocating memory and computation, allowing matrix-vector operations to occur directly where weights are stored. Photonic computing similarly explores the use of light to accelerate matrix multiplication and related linear operations. Neuromorphic systems pursue sparse, event-driven computation that may be valuable for real-time perception and robotics.
These technologies suggest a broader design principle: hardware should not always be forced to imitate general-purpose software. Instead, models and algorithms may be co-designed to fit the mathematical strengths of the physical substrate.
Conventional digital computing treats noise as an error to be eliminated. Neural inference is different. Many neural networks operate through approximate continuous activations, distributions, thresholds, rankings, and probabilistic outputs. This does not mean arbitrary noise is safe. Bias, drift, systematic error, and rare large deviations can still be dangerous. However, bounded stochasticity may be tolerable if the model is trained and monitored appropriately.
Hardware-aware training already points in this direction. Rather than training a model under ideal mathematical assumptions and then deploying it onto imperfect hardware, hardware-aware training incorporates realistic hardware nonidealities during retraining or adaptation. This suggests that future inference systems may become more reliable by learning the statistical character of the hardware itself.
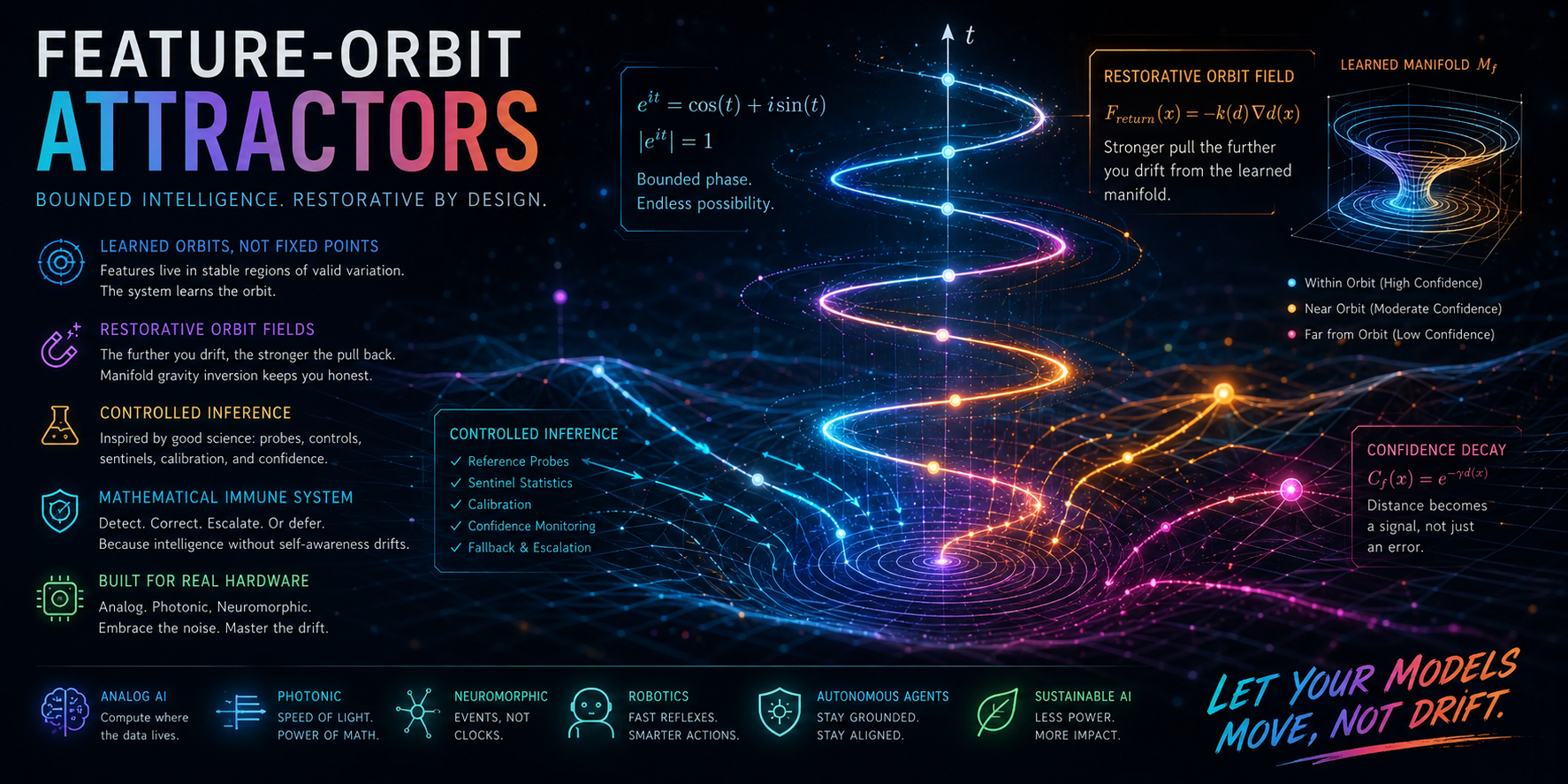
Controlled Inference
Scientific experimentation often attempts to isolate variables by using controls. A known independent variable is manipulated, a dependent variable is observed, and unwanted variables are minimized or statistically accounted for. This same principle can be adapted to inference.
In controlled inference, each inference pass is treated as a partially controlled experiment. The user input is the primary independent variable. The model output is the dependent variable. Unwanted variables include analog drift, thermal variation, quantization error, device aging, noise accumulation, bias, memory corruption, and compounding internal-state error.
A controlled inference system would therefore include reference probes, negative and positive controls, differential computation paths, sentinel statistics, live calibration, hardware-aware adaptation, confidence degradation, and digital or higher-precision fallback.
The goal is not perfect noiseless inference. The goal is bounded, monitored, correctable inference.
Eulerian Phase, Bounded Motion, and the Helix Analogy
Euler’s formula provides a useful conceptual image:
\[ e^{it} = \cos(t) + i\sin(t) \]
In the complex plane, this traces the unit circle. Its magnitude remains bounded:
\[ |e^{it}| = 1 \]
If the parameter \(t\) is interpreted as time or angle and lifted into a third axis, the path becomes a helix:
\[ p(t) = \bigl(\cos(t),\ \sin(t),\ \alpha t\bigr) \]
This helix is a useful metaphor for bounded variation. The system changes continuously, yet part of its behavior remains constrained. The angle or phase changes, but the radius remains bounded.
This paper does not claim that AI representations should literally be helices. Rather, the helix illustrates a more general engineering idea: a system may be allowed to change over time while remaining constrained to a stable orbit, manifold, or bounded region.
In AI inference, this suggests that internal representations should not necessarily be pulled toward a single fixed point. A rigid point attractor may destroy useful variation. Instead, a learned feature may be represented as a valid region of motion, an orbit, or a manifold.
Feature-Orbit Attractors
A feature-orbit attractor is a proposed representational structure in which a learned feature is associated not merely with a point, but with a stable region of valid variation.
Instead of representing a feature as:
\[ x = \text{ideal} \]
the system represents it as:
\[ x \in M_f \]
where \(M_f\) is the learned manifold, orbit, or valid representational region associated with feature \(f\).
The distance from the current representation \(x\) to the feature manifold can be defined conceptually as:
\[ d_f(x) = \min_{y \in M_f} \lVert x - y \rVert \]
A system can then apply a restorative force when \(x\) drifts too far from \(M_f\).
Restorative Orbit Fields
The proposed corrective field is intentionally different from gravity. Gravity grows stronger as objects get closer to the source. In this framework, the corrective force grows stronger as the representation moves farther away from its learned valid region.
A simple conceptual form is:
\[ F_{\text{return}} \propto d \]
or, more aggressively:
\[ F_{\text{return}} \propto d^2 \]
A more geometric expression is:
\[ F_{\text{return}}(x) = -k\bigl(d_f(x)\bigr)\nabla d_f(x) \]
where \(k(d)\) is a gain function that increases with distance from the learned manifold.
This creates a restorative orbit field. Small deviations are tolerated. Moderate deviations are gently corrected. Large deviations trigger strong correction, confidence reduction, or rerouting.
This may be described as manifold gravity inversion: the farther a representation drifts from its lawful orbit, the stronger the pullback becomes.
Confidence and Escalation
A feature-orbit system should not always forcibly correct uncertain states. Some deviations may represent genuinely novel inputs, ambiguous cases, adversarial prompts, or domain shifts. Therefore, distance from a learned feature orbit should also contribute to confidence estimation.
A simple confidence function might be:
\[ C_f(x) = \exp\bigl(-\gamma d_f(x)\bigr) \]
where \(\gamma\) controls how rapidly confidence decays with distance from the feature manifold.
When confidence falls below a threshold, the system may rerun the computation at higher precision, consult a digital verifier, escalate to a larger model, ask for clarification, refuse to act autonomously, or log the event for future calibration.
This turns representational drift into an observable safety signal rather than a hidden failure mode.
Controlled Inference in Analog and Mixed-Signal Hardware
Analog and mixed-signal AI systems may benefit from this framework because they face unavoidable nonidealities. Rather than treating such imperfections as exceptional faults, the inference system can characterize and monitor them.
Known input vectors can be periodically passed through analog compute blocks as reference probes. If the observed output differs from the expected output, the system estimates current drift.
Let \(z_j\) be a reference probe and \(y_j\) be its expected output. If \(A_t\) is the current hardware computation, the probe error is:
\[ e_j(t) = A_t(z_j) - y_j \]
This error can be used to update calibration parameters.
A negative control is an input expected to produce minimal activation in a target channel or feature region. A positive control is expected to produce strong activation. If negative controls begin activating or positive controls weaken, the system has evidence of drift, bias, saturation, or noise.
Differential paths can compare a signal to a matched reference signal. Common-mode noise, thermal variation, and shared bias can be partially canceled by measuring relative differences rather than absolute values.
Sentinel layers or monitoring processes can observe activation statistics between major blocks: mean, variance, entropy, norm, sparsity, feature-distance, distribution collapse, and unexpected channel dominance. If internal states leave expected ranges, the system can correct, reroute, or reduce confidence.
Each physical AI accelerator may have its own measurable quirks: noisy regions, drifting cells, temperature sensitivity, aging patterns, or calibration history. A hardware temperament profile would store this information and allow the model to adapt to the specific device it is running on. This is analogous to maintaining a calibration history for a scientific instrument.
Training Objective
The proposed framework could be incorporated into training or adaptation through additional loss terms.
A conceptual total loss might be:
\[ L_{\text{total}} = L_{\text{task}} + \lambda \mathbb{E}\left[d_f(h)^p\right] + \mu L_{\text{control}} + \rho L_{\text{confidence}} \]
where \(L_{\text{task}}\) is the ordinary task loss, \(h\) is an internal representation, \(d_f(h)\) is the distance from \(h\) to a learned feature manifold, \(p\) controls how sharply large deviations are penalized, \(L_{\text{control}}\) penalizes failure on reference probes or sentinel checks, and \(L_{\text{confidence}}\) encourages uncertainty when the system leaves known manifolds.
The purpose is not to make all representations collapse into a small space. The purpose is to teach the system the difference between valid variation and unstable drift.
Relationship to Existing Ideas
This framework is conceptually related to attractor networks, energy-based models, manifold learning, denoising models, control theory, rotary position embeddings, hardware-aware training, and error-compensation methods for analog neural networks.
The novelty here is not any single mathematical component. The proposed contribution is the combined conceptual architecture: bounded feature-orbits, nonlinear restorative forces, scientific controls, hardware temperament profiles, and confidence-based escalation.
Representational Reflex Circuitry
In robotics, a useful design pattern is reflex circuitry: fast, local responses handle immediate corrections before slower central reasoning intervenes. A similar idea can be applied inside AI representation space.
Representational reflex circuitry would detect drift, instability, or feature-orbit departure at low levels of the inference system. It would apply corrective forces or escalation signals before higher-level reasoning produces a confident but invalid output.
This may be especially useful for analog AI hardware, local robotics systems, autonomous agents, long-context language models, always-on edge devices, low-power sensor systems, and safety-critical embedded inference.
The purpose is not to replace reasoning. The purpose is to keep the representational substrate healthy enough that reasoning remains grounded.
Possible Applications
Small local devices may use analog or mixed-signal accelerators for common inference tasks while relying on feature-orbit monitors to detect drift and uncertainty.
Robots need fast, continuous, low-power perception and control. Representational reflex circuitry could help maintain stable sensor interpretation while higher-level planning operates more slowly.
Autonomous agents can drift over time through memory accumulation, repeated assumptions, and feedback loops. Feature-orbit attractors could provide internal checks against runaway interpretation or self-reinforcing bias.
Analog compute-in-memory systems could use reference probes, sentinel statistics, and hardware-aware training to reduce error accumulation and improve reliability.
Bias is not merely noise. It can arise from training data, objectives, labels, context, and feedback. However, some forms of bias may manifest as measurable representational drift. Feature-orbit distance and confidence decay could help identify when a model is leaving a learned valid region.
Limitations and Risks
This framework is conceptual and untested. Several risks must be acknowledged.
A bounded system may still be biased if the learned manifold itself encodes bias. Restorative forces may suppress novelty if thresholds are too strict. Poorly learned feature-orbits could create false confidence. Hardware calibration may become complex and device-specific. Some AI failures occur at semantic or social levels that cannot be solved by representational geometry alone. Corrective systems may hide errors rather than reveal them if monitoring is poorly designed.
Therefore, feature-orbit attractors should not be treated as a complete safety solution. They are better understood as one possible layer in a larger reliability architecture.
Research Directions
The framework suggests several possible experiments:
- Train small neural models with learned feature manifolds and nonlinear distance penalties.
- Compare point attractors, manifold attractors, and orbit-like attractors for robustness under noise.
- Inject analog-style noise during inference and measure whether restorative orbit fields reduce error propagation.
- Build sentinel statistics that predict when inference results become unreliable.
- Simulate hardware temperament profiles and evaluate whether device-specific calibration improves accuracy.
- Test whether confidence based on manifold distance correlates with hallucination or task failure.
- Explore whether phase-based or rotational representations improve stability under long-context drift.
- Evaluate local robotics perception pipelines using representational reflex circuitry.
Conclusion
Future AI systems may need to become smaller, faster, less power-hungry, and more tolerant of imperfect hardware. Analog, photonic, neuromorphic, and mixed-signal inference systems may help, but only if models are designed to operate under realistic physical conditions.
This paper proposes a conceptual framework for bounded, self-correcting inference. Learned feature-orbits represent valid regions of internal variation. Restorative orbit fields apply increasing correction as representations drift away from those regions. Controlled inference uses scientific-control principles to measure and compensate for hardware and representational instability. Hardware temperament profiles allow physical devices to be treated as calibrated instruments rather than interchangeable ideal machines. Representational reflex circuitry provides fast internal correction before high-level reasoning compounds errors.
In short: AI inference may be made more robust by giving its thoughts room to move, but not infinite permission to drift.
The desired system is not rigid. It is bounded. It is not noiseless. It is calibrated. It is not merely intelligent. It has a homing instinct.
Suggested Term List
- Feature-Orbit Attractor
- A learned manifold or orbit representing valid variation around a feature.
- Restorative Orbit Field
- A nonlinear corrective field that strengthens as representation drift increases.
- Manifold Gravity Inversion
- A correction principle where distance from the learned manifold increases pullback force.
- Controlled Inference
- Inference treated as a monitored experiment with controls, probes, and fallback paths.
- Hardware Temperament Profile
- A device-specific calibration history describing drift, noise, aging, and nonideal behavior.
- Representational Reflex Circuitry
- Fast internal correction mechanisms that stabilize representations before higher-level reasoning compounds error.
- Mathematical Immune System
- A broad metaphor for internal detection, correction, confidence reduction, and rerouting when inference becomes unstable.
References and Source Notes
- International Energy Agency. Energy and AI. https://www.iea.org/reports/energy-and-ai/energy-demand-from-ai
- IBM Research. In-memory computing approaches for large language model acceleration. https://research.ibm.com/publications/in-memory-computing-approaches-for-large-language-model-acceleration
- Xu, X. et al. 11 TOPS photonic convolutional accelerator for optical neural networks, Nature. https://www.nature.com/articles/s41377-022-00717-8
- Intel Newsroom. Intel Builds World’s Largest Neuromorphic System to Enable More Sustainable AI. https://newsroom.intel.com/artificial-intelligence/intel-builds-worlds-largest-neuromorphic-system-to-enable-more-sustainable-ai
- Nature Communications. Hardware-aware training for large-scale and diverse deep learning inference workloads using in-memory computing-based accelerators. https://www.nature.com/articles/s41467-023-40770-4
- Su, J. et al. RoFormer: Enhanced Transformer with Rotary Position Embedding. https://arxiv.org/abs/2104.09864
- CorrectNet. Training-time error suppression and compensation for analog neural network inference. https://past.date-conference.com/proceedings-archive/2023/DATA/664.pdf
AIT